LiTo:
Surface Light Field Tokenization
LiTo tokenizes surface light fields into a compact latent representation, enabling high-quality 3D reconstruction and image-to-3D generation from sparse views. A novel paradigm that bridges light field rendering with autoregressive token prediction.
What makes LiTo different from other 3D representations
LiTo rethinks 3D representation by encoding appearance and geometry jointly through surface light field tokenization, avoiding the limitations of volumetric or point-based approaches.
Surface-grounded encoding
Tokens are anchored to the object surface rather than distributed across a volume, which concentrates representational capacity where it matters.
Joint geometry & appearance
Each token encodes both spatial position and view-dependent appearance, enabling the model to capture complex specular and reflective surfaces.
Autoregressive generation
The tokenized representation feeds into a standard autoregressive transformer, making generative 3D modeling tractable with existing infrastructure.
Qualitative results on 3D reconstruction
Comparison between LiTo and TRELLIS (Xiang et al., 2025) on surface light field reconstruction from sparse input views.

Single-image to 3D asset generation
LiTo produces 3D assets from a single conditioning image while respecting the camera coordinate system. Note that TRELLIS does not respect the camera coordinate system, so sometimes their output objects will be oriented incorrectly.

Side-by-side viewer examples
Click each image to open the side-by-side 3DGS viewer for comparison between LiTo and TRELLIS (Xiang et al., 2025).
Apple (reconstruction) — The 3D asset is created by DigitalSouls and distributed under CC Attribution-NonCommercial license.
Steampunk (generation) — The 3D asset is created by 3d-coat and distributed under CC Attribution license.

Beetle (generation) — The given input image is AI-generated.

Bone (generation) — The given input image is captured in the wild.
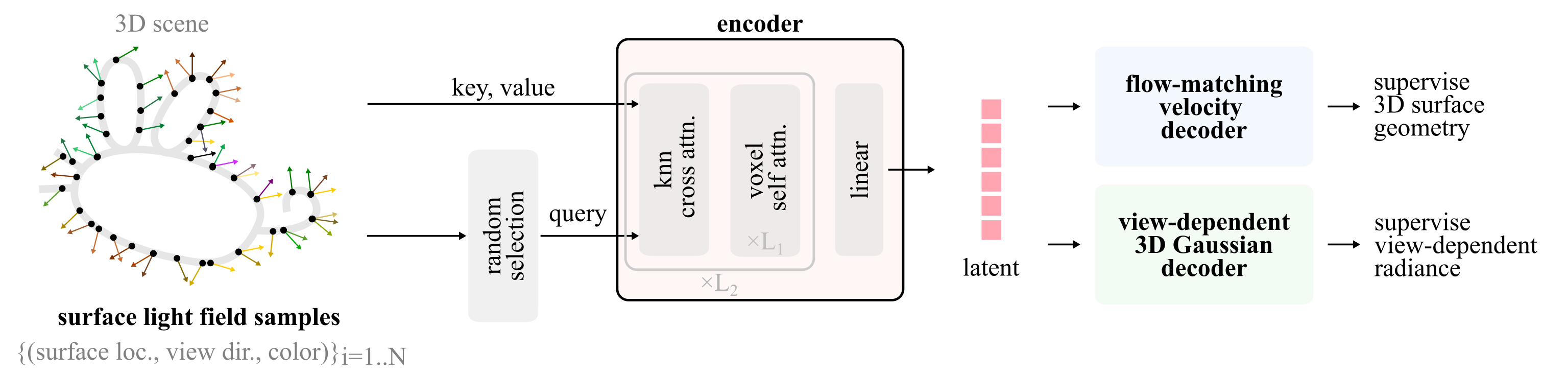
Tokenizing surface light fields in four steps
A compact pipeline that turns sparse image inputs into a tokenized surface light field ready for autoregressive modeling.
Surface extraction
A coarse surface geometry is estimated from sparse input views using a lightweight reconstruction network, providing a spatial anchor for subsequent tokens.
Light field sampling
View-dependent radiance is sampled at surface-adjacent points across multiple input viewpoints, producing a dense set of appearance features tied to surface locations.
Tokenization
The sampled features are quantized into a discrete token sequence via a learned codebook, compressing the continuous light field into a compact discrete representation.
Autoregressive modeling
A causal transformer models the token sequence, enabling both reconstruction (encoding → decoding) and generation (sampling from the prior) within a unified framework.
It turns 3D reconstruction into a token prediction problem
Most 3D representations require specialized rendering engines or volumetric sampling. LiTo reformulates the problem so that any autoregressive model can generate and reconstruct 3D scenes.
Unified framework
The same token representation supports both reconstruction from sparse views and unconditional or conditional generation.
View-dependent effects
Surface light fields naturally encode specular highlights, reflections, and transparency that volumetric methods struggle to represent.
Scalable architecture
Leverages standard transformer infrastructure — no custom rendering passes, no volumetric ray marching, no differentiable rasterizers.
What Is LiTo? How Surface Light Field Tokenization Works
A clear explanation of what LiTo is, who built it, how the tokenization pipeline works, and how to use it.
Paper overview
LiTo introduces a method for representing 3D objects as discrete token sequences over surface light fields. The approach first extracts a coarse surface from sparse input images, samples view-dependent radiance at surface-adjacent points, quantizes these features into tokens via a learned codebook, and models the token sequence with a causal transformer.
The resulting representation supports both reconstruction — encoding input views and decoding novel views — and generation, where tokens are sampled from the learned prior to produce new 3D assets from scratch or from a conditioning image.
Key contributions
A surface-grounded tokenization scheme that concentrates representational capacity on the object surface; joint encoding of geometry and view-dependent appearance within each token; and an autoregressive formulation that unifies reconstruction and generation under a single modeling framework.
Published at ICLR 2026 as a spotlight paper.
The fastest answers to the questions people ask first
Start here if you want the creators, the method, or the training details without reading the full paper first.
Who created LiTo?
LiTo comes from Jen-Hao Rick Chang, Xiaoming Zhao, Dorian Chan, and Oncel Tuzel at Apple. The project is published at ICLR 2026.
What is surface light field tokenization?
Surface light field tokenization encodes a 3D object's appearance from multiple viewpoints into a discrete token sequence anchored to the object's surface, rather than representing it in a volumetric grid or as a point cloud.
How does LiTo compare to TRELLIS?
LiTo respects the camera coordinate system — TRELLIS sometimes orients objects incorrectly. LiTo also achieves higher-quality novel-view synthesis and more faithful reconstruction from sparse inputs.
Can LiTo generate 3D assets from a single image?
Yes. LiTo supports image-to-3D generation by conditioning the autoregressive model on a single input image, producing a full 3D asset with view-dependent appearance.
What hardware is needed to run LiTo?
Training details and hardware requirements are described in the paper. The autoregressive transformer component runs on standard GPU hardware used for large language model training.
BibTeX
@inproceedings{chang2026lito,
author = {Jen-Hao Rick Chang$^\ast$ and Xiaoming Zhao$^\ast$ and Dorian Chan and Oncel Tuzel},
title = {{LiTo: Surface Light Field Tokenization}},
booktitle = {International Conference on Learning Representations},
year = {2026},
}